Today I was working with Django and MySQL using "ENVIRONMENTVARIABLE". But when I was trying to sync my MySQL db. It was generating a error. something like this.
(test_south) C:\Users\a\Envs\test_south\test_project>python manage.py syncdb
Traceback (most recent call last):
File "manage.py", line 10, in <module>
execute_from_command_line(sys.argv)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 453, in execute_from_command_line
utility.execute()
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 392, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 272, in fetch_command
klass = load_command_class(app_name, subcommand)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 77, in load_command_class
module = import_module('%s.management.commands.%s' % (app_name, name))
File "C:\Users\a\Envs\test_south\lib\site-packages\django\utils\importlib.py", line 35, in import_module
__import__(name)
File "C:\Users\a\Envs\test_south\lib\site-packages\south\management\commands\__init__.py", line 12, in <module>
from south.hacks import hacks
File "C:\Users\a\Envs\test_south\lib\site-packages\south\hacks\__init__.py", line 8, in <module>
from south.hacks.django_1_0 import Hacks
File "C:\Users\a\Envs\test_south\lib\site-packages\south\hacks\django_1_0.py", line 6, in <module>
from django.db.backends.creation import BaseDatabaseCreation
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\__init__.py", line 40, in <module>
backend = load_backend(connection.settings_dict['ENGINE'])
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\__init__.py", line 34, in __getattr__
return getattr(connections[DEFAULT_DB_ALIAS], item)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\utils.py", line 93, in __getitem__
backend = load_backend(db['ENGINE'])
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\utils.py", line 27, in load_backend
return import_module('.base', backend_name)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\utils\importlib.py", line 35, in import_module
__import__(name)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\backends\mysql\base.py", line 17, in <module>
raise ImproperlyConfigured("Error loading MySQLdb module: %s" % e)
django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module: No module named _mysql
Then I was trying to install MySQLdb using pip command. My pip command was: pip install MySQL-python. But at time I faced a another problem. Like
building '_mysql' extension
C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\BIN\amd64\cl.exe /c /nologo /Ox /MD /W3 /GS- /DNDEBUG -Dversion_info=(1,2,4,'final',1) -D__versi
on__=1.2.4 "-IC:\Program Files\MySQL\Connector C++ 1.1.3\include" -IC:\Python27\include -IC:\Users\a\Envs\test_south\PC /Tc_mysql.c /Fobuild\temp.win-
amd64-2.7\Release\_mysql.obj /Zl
_mysql.c
_mysql.c(42) : fatal error C1083: Cannot open include file: 'config-win.h': No such file or directory
error: command '"C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\BIN\amd64\cl.exe"' failed with exit status 2
How could I solved this problem?
1] First I went to the http://www.codegood.com/download/11/ this location to download the binary of mysql-python64bit. Which is MySQL-python-1.2.3.win-amd64-py2.7.exe
2] Then I installed the binary in my C:\Python27 folder location
3] Then I went to the Lib\site-package folder and copy all the files and folder which are related to the mysql
 4] Then I just paste the files in my environmentvariable location. which is
4] Then I just paste the files in my environmentvariable location. which is

then pressed the syncdb command. And it was working :-)
(test_south) C:\Users\a\Envs\test_south\test_project>python manage.py syncdb
Traceback (most recent call last):
File "manage.py", line 10, in <module>
execute_from_command_line(sys.argv)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 453, in execute_from_command_line
utility.execute()
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 392, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 272, in fetch_command
klass = load_command_class(app_name, subcommand)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\core\management\__init__.py", line 77, in load_command_class
module = import_module('%s.management.commands.%s' % (app_name, name))
File "C:\Users\a\Envs\test_south\lib\site-packages\django\utils\importlib.py", line 35, in import_module
__import__(name)
File "C:\Users\a\Envs\test_south\lib\site-packages\south\management\commands\__init__.py", line 12, in <module>
from south.hacks import hacks
File "C:\Users\a\Envs\test_south\lib\site-packages\south\hacks\__init__.py", line 8, in <module>
from south.hacks.django_1_0 import Hacks
File "C:\Users\a\Envs\test_south\lib\site-packages\south\hacks\django_1_0.py", line 6, in <module>
from django.db.backends.creation import BaseDatabaseCreation
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\__init__.py", line 40, in <module>
backend = load_backend(connection.settings_dict['ENGINE'])
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\__init__.py", line 34, in __getattr__
return getattr(connections[DEFAULT_DB_ALIAS], item)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\utils.py", line 93, in __getitem__
backend = load_backend(db['ENGINE'])
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\utils.py", line 27, in load_backend
return import_module('.base', backend_name)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\utils\importlib.py", line 35, in import_module
__import__(name)
File "C:\Users\a\Envs\test_south\lib\site-packages\django\db\backends\mysql\base.py", line 17, in <module>
raise ImproperlyConfigured("Error loading MySQLdb module: %s" % e)
django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module: No module named _mysql
Then I was trying to install MySQLdb using pip command. My pip command was: pip install MySQL-python. But at time I faced a another problem. Like
building '_mysql' extension
C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\BIN\amd64\cl.exe /c /nologo /Ox /MD /W3 /GS- /DNDEBUG -Dversion_info=(1,2,4,'final',1) -D__versi
on__=1.2.4 "-IC:\Program Files\MySQL\Connector C++ 1.1.3\include" -IC:\Python27\include -IC:\Users\a\Envs\test_south\PC /Tc_mysql.c /Fobuild\temp.win-
amd64-2.7\Release\_mysql.obj /Zl
_mysql.c
_mysql.c(42) : fatal error C1083: Cannot open include file: 'config-win.h': No such file or directory
error: command '"C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\BIN\amd64\cl.exe"' failed with exit status 2
How could I solved this problem?
1] First I went to the http://www.codegood.com/download/11/ this location to download the binary of mysql-python64bit. Which is MySQL-python-1.2.3.win-amd64-py2.7.exe
2] Then I installed the binary in my C:\Python27 folder location
3] Then I went to the Lib\site-package folder and copy all the files and folder which are related to the mysql

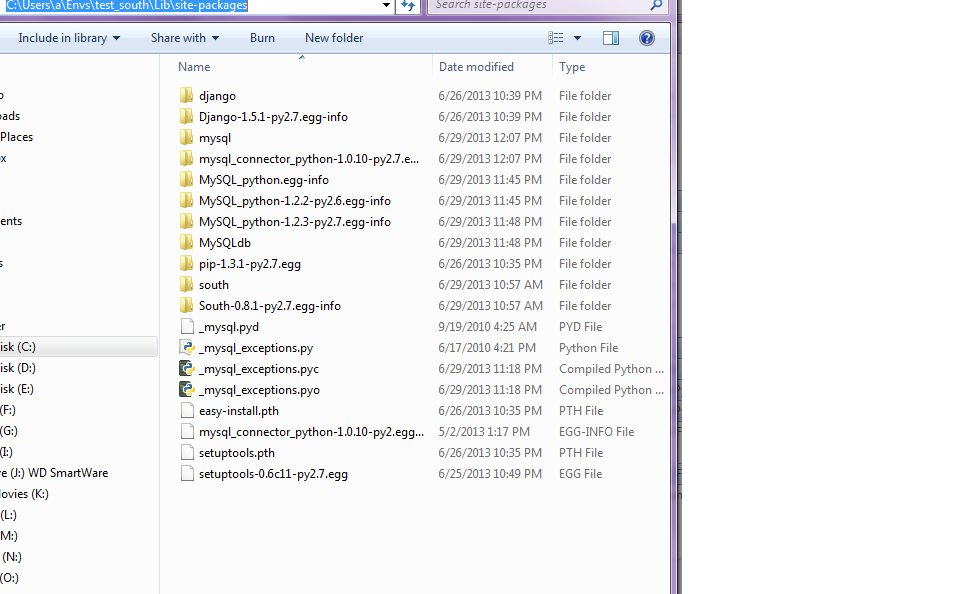
then pressed the syncdb command. And it was working :-)
































